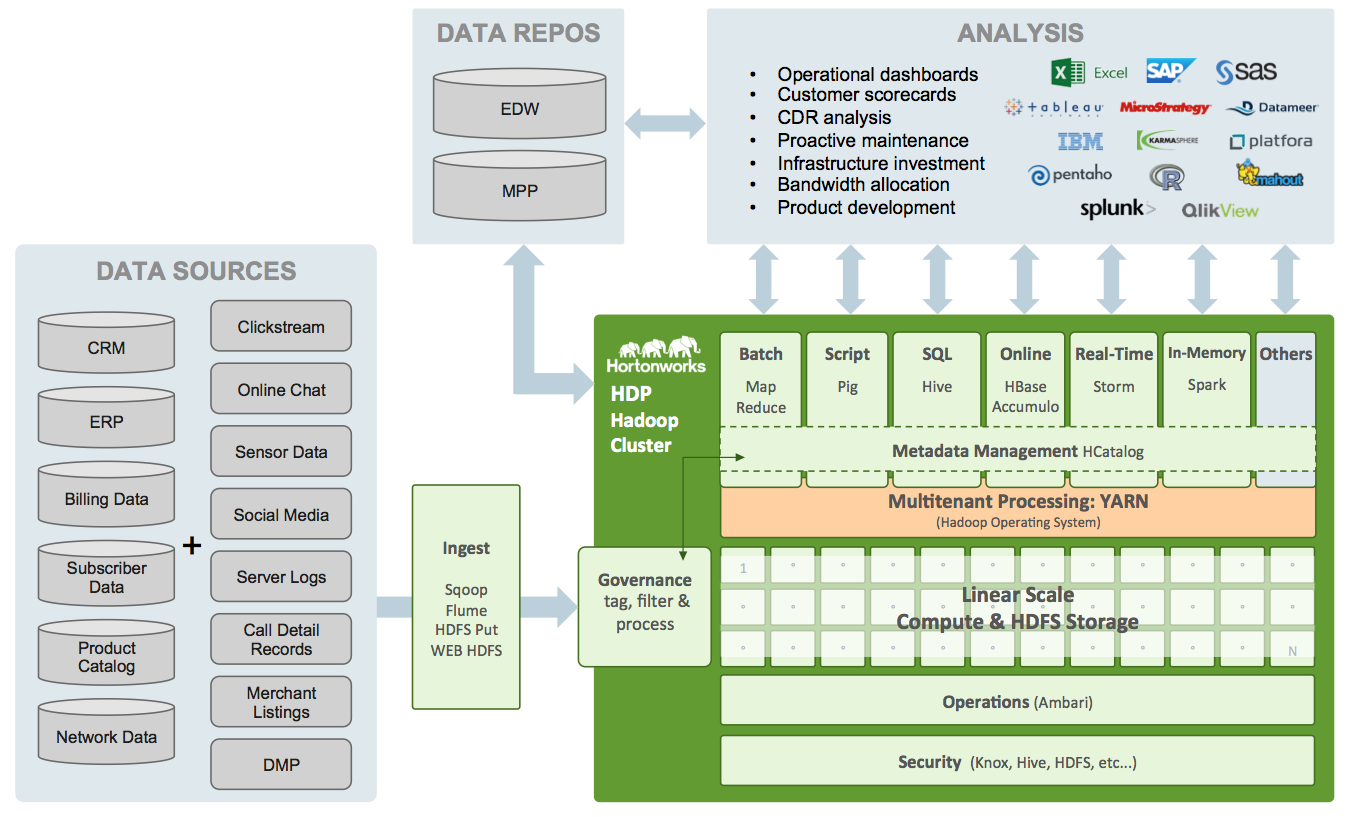
Hadoop platform is composed by different components and tools.
Hadoop HDFS: A distributed file system that partitions large files across multiple machines for high throughput access to data.
Hadoop YARN; A framework for job scheduling and cluster resource management.
Hadoop map reduce; A programming framework for distributed batch processing of large data sets distributed across multiple servers.
Hive; A data warehouse system for Hadoop that facilitates data summation, ad-hoc queries, and the analysis of large data sets stored in Hadoop – compatible file systems. Hive provides a mechanism to project structure onto this data and query it using a SQL-like language called HiveQL. HiveQL programs are converted into MapReduce programs. Hive was initially developed by Facebook.
HBase; An open-source, distributed, column oriented store modeler created after google’s big table (that is property of Google). HBase is written in Java.
Pig; A high-level data-flow language (commonly called “Pig Latin”) for expressing MapReduce programs; it’s used for analyzing large HDFS distributed data sets. Pig was originally developed at Yahoo Research around 2006.
Mahout; A scalable machine learning and data mining library.
Oozie; A workflow scheduler system to manage Hadoop jobs (MapReduce and Pig jobs). Oozie is implemented as a Java Web-Application that runs in a Java Servlet-Container.
Spark; It’s a cluster computing framework which purpose is to manage large scale of data in memory. Spark’s in-memory primitives provide performance up to 100 times faster for certain applications.
Zookeeper; It’s a distributed configuration service, synchronization service, and naming registry for large distributed systems.