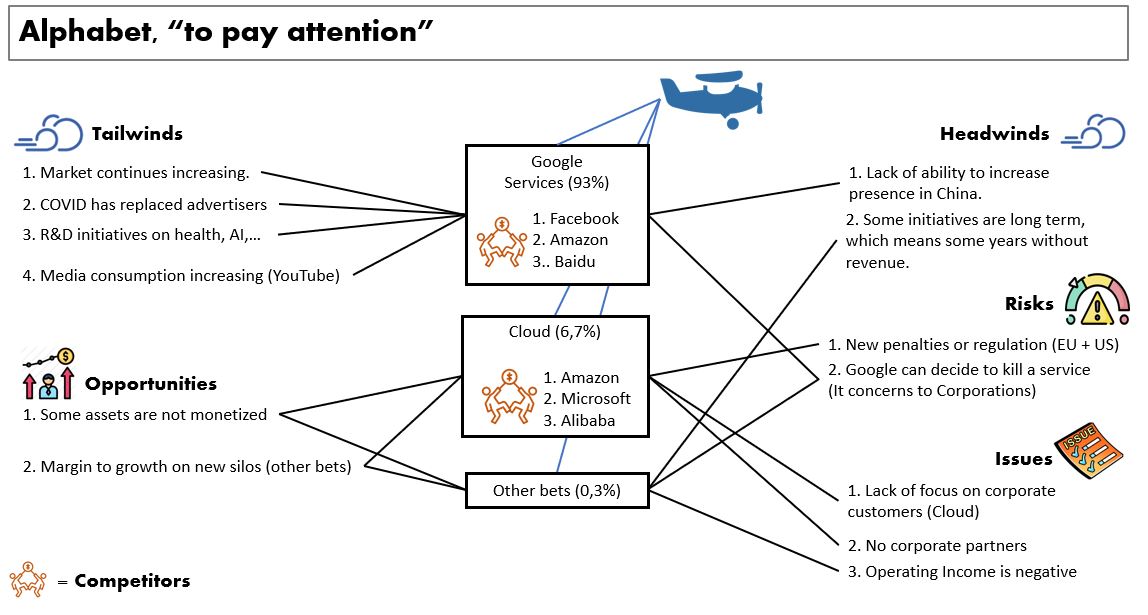
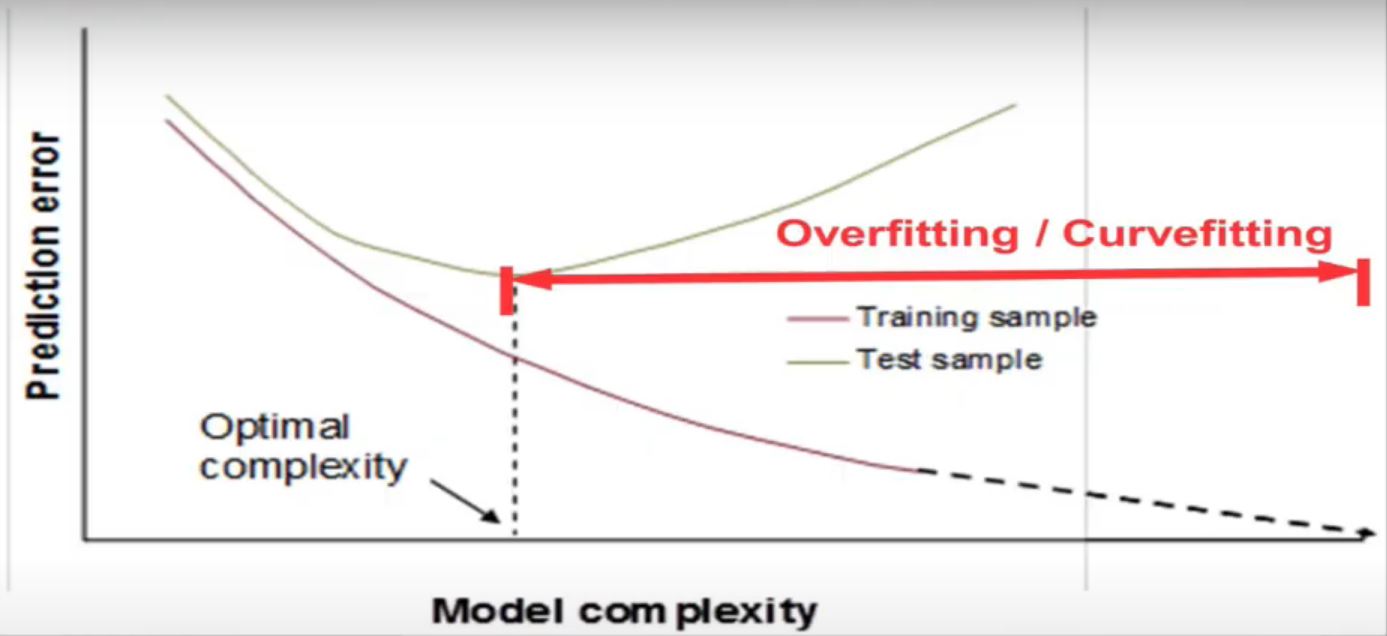
Koncorde Big Players + DarkPool Index
This code is an indicator composed by 2 pieces of code that have been combined. Big players by Konkorde that are buying (https://www.blai5.net/blai5-koncorde-la-importancia-del-volumen/) DarkPool Index when it’s over 35% (https://squeezemetrics.com/monitor/download/pdf/short_is_long.pdf?) The individual goal of these indicators is to point to big player buying. So what if we combine the 2 indicators? The code An example … Read more