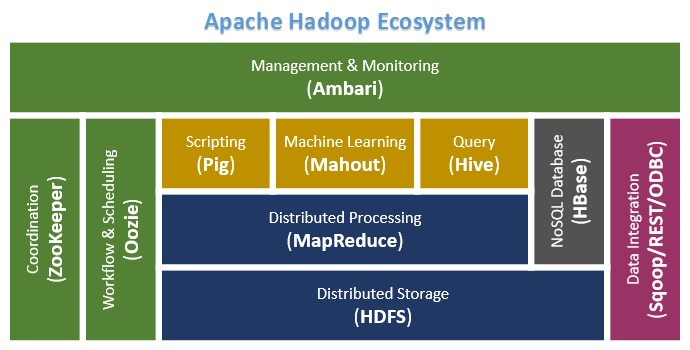
My learning on the basic concepts of Hadoop continues.
Pig has 2 basic elements:
- Pig Latin, it’s a data flow language used by programmers to write pig programs
- Pig Latin compiler: converts pig latin code into executable code. Executable code is in form of MapReduce jobs or it can spawn a process where virtual Hadoop instance is created to run pig code on single node.
Pig works along with other Hadoop elements as HDSF, MapReduce Framework, YARN…
You can create Macros in Pig Language, you can also access to the piggybank to use standard code.
The main difference between MapReduce V1 and V2 is the existence of YARN
Pig vs. SQL
- Pig Latin is procedural, SQL is declarative.
- In pig you can have bag of tuples and the can be duplicated; In SQL on a set of tuples, every tuple is unique.
- In Pig you can have different number of columns.
- Pig uses ETL natively; SQL requires a separate ETL tool.
- Pig uses lazy evaluation. In RDBMS you only have instant invocation of commands.
- In Pig there is not control statements as “if” and “else”.
- Pig Latin allows pipeline developers to decide where to checkpoint data in the pipeline and you can store data at any point during a pipeline. Most RDBMS systems have limited or no pipeline support. SQL is oriented around queries that produce a single result.