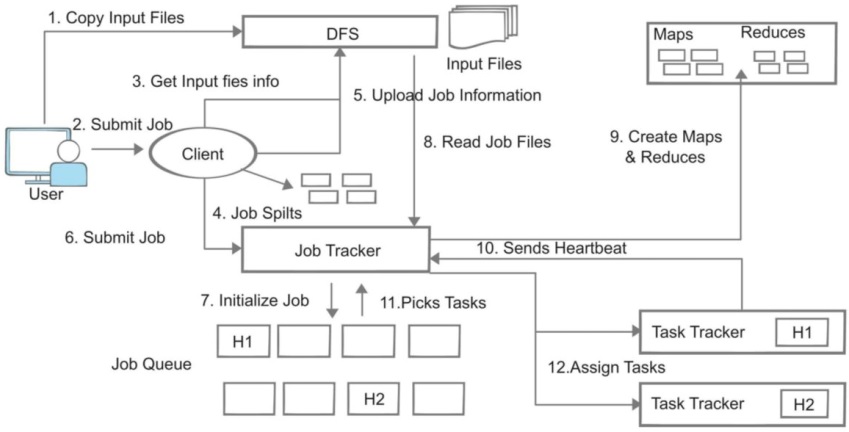
In the process of understanding the basis of Hadoop I found a training course in AWS that is helping me to understand the concepts.
- Map: it’s a process to map all distributed blocks of data and send the requested job to each one of them. The job sent to the block is a task with a reference to that block.
- Reduce: it’s an iterative process where all data output from a task is sent back to summarize or join all the information into an unique place.
- #Replication factor = 3. This means that every data block is replicated 3 times. With it, if a data block fails, another is available.
- Jobs are divided in tasks that are sent to different blocks.
- The block size by default is 64Mb.