Why these projects are important?
Many statistics say the consumer buys more when multimedia information they consume to decide if to purchase or not, is greater when the it’s provided in the local language.
This is not the only situation when you are consuming information where the sender wants your attention (one of the major challenges in today’s world). Other situations where you want to capture user attention can be:
- Training, through instructional videos, product and training materials.
- Communications, through corporate videos, online presentations, flash-based presentations.
- Sales, through marketing, sales, online presentations or demos.
This makes the content providers to not only provide information in English or the original language they come from, but in as much languages as possible.
To do it, is a challenge.
Project requirements and other considerations
There are different challenges depending on the context of the project, the tools available to build the solution and the amount & quality of content you have in scope.
- Requirements as continuous translation and online translation makes the project have a clear approach: you have to automate.
- For massive content initiatives the solution should contain a combination of Machine Learning and person intervention to improve and enrich the text corpus.
- The complexity given by the number of languages to cover is key too.
- Data quality, this needs to be checked, and you at least should be able to define the thresholds of quality you are requiring (when you have the option to define them, that is not always possible).
Solution approach
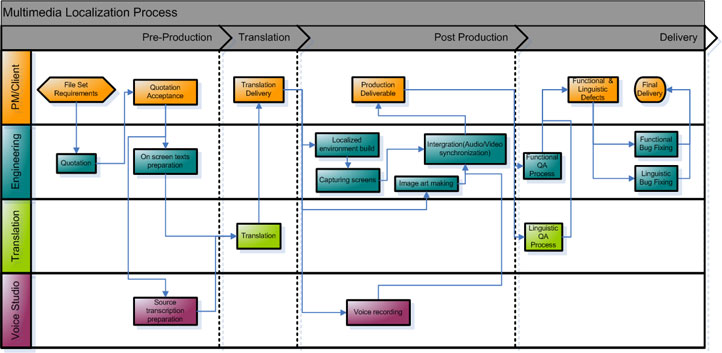
Realfond explains the steps for a multimedia localization project.
Example with AWS, solution components
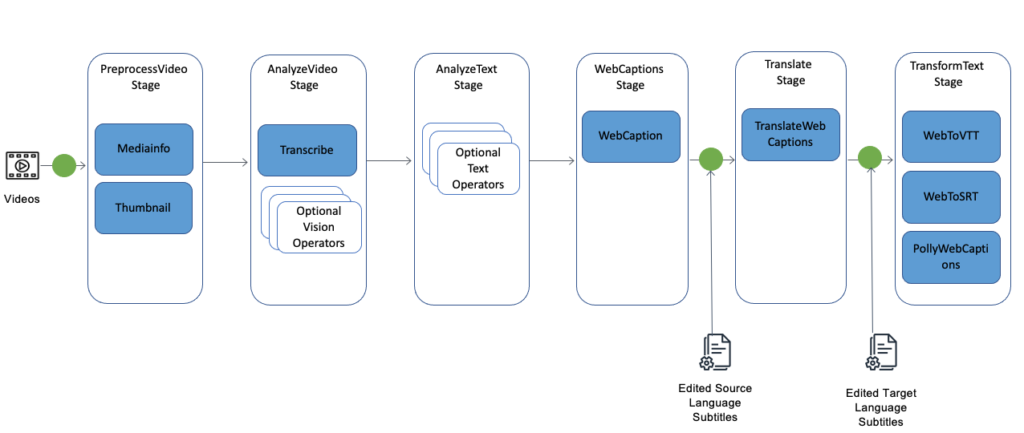
During the analysis of the video, with Transcribe, we can:
- Add custom vocabulary: provide Amazon Transcribe with a list of terms that are specific to your content.
- Add custom language models: provide Amazon Transcribe with text data (training data) to improve transcription accuracy for industry-specific terms, acronyms, and other phrases that it might not otherwise recognize.
MIE operators analyze and/or transform the input video. There are different types of operators:
Mediainfo– analyze the video package and provides information about the format of the video.Thumbnail– uses AWS MediaConvert to generate thumbnail images.TranscribeVideo– generates a transcript of the spoken audio in the video using Amazon Transcribe.WebCaptions– converts the transcript generated by Amazon Transcribe into subtitle blocks.
Other components:
- Web to VTT = Web to video Text Tracks
- Web to SRT = Web to SubRip File Format (subtitle format)
The solution approach proposed by AWS using their content localization service provides a lot of automation to the final solution, but it requires to implement the machine learning solution, with proper accuracy and the rest of the components.