The project approach is defined by the lifecycle of the solution, and here I will focused just on the machine learning side of the project (other sections as infrastructure, education, operations…) will not be reviewed here.
What is the lifecycle of a Machine Learning solution?
The lifecycle is sequential and in reality is can be repeated as many times as required.
The execution of a ML project depends on if this is the first project or if this is a specific project scope under a program or a portfolio that is already running. This is critical and .change the whole project approach and difficulties of the project manager.
The platform used to host the solution will vary the steps of the cycle a little bit. If so, my suggestion is to adapt to what the platform suggest.
The lifecycle of a Machine Learning solution
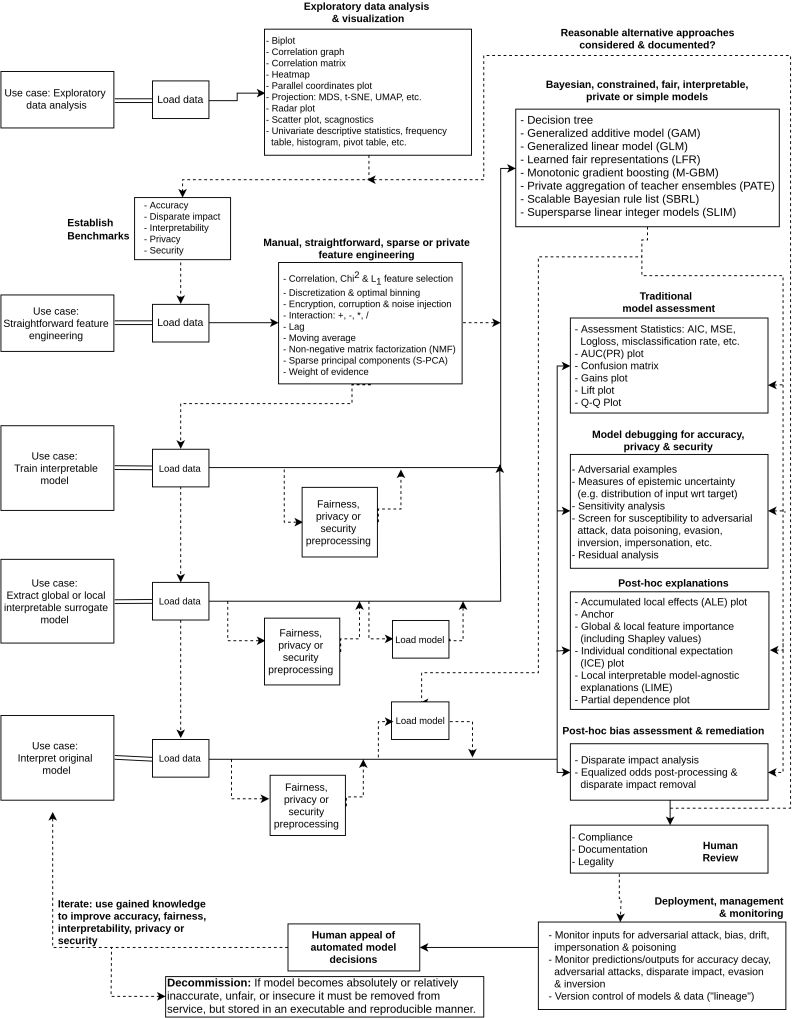
This is the basic lifecycle of a machine learning solution.
- Problem Definition: you are trying to solve a business problem; define the business objectives, the success criteria and the environmental factors that are part of the scenario. Many times this is already defined in the business case that provides the budget and authority to your project.
- Data exploration: Define the sources of data required for your project, define the steps for data extraction, confirm data availability, define potential data protection issues, and define the quality and quantity of data available.
- Data preparation: Initial work starts with statistical analysis, definition of different strategies to prepare the data and how to maintain the integrity. This step is being reviewed many times, and is in constant evolution as the project progress. You define the training data sets and the testing data sets, and the use criteria. Here the data labelling is done.
- Model exploration: Evaluate several key factors regarding data: its complexity, its diversity, distributions, its quality, freshness and the existence of potential bias. You probably will start the model definition here with main ideas that show up during the analysis.
- Model training: You have defined a model and you train it, understand the results, analyze them, continue model exploration and repeat it again. Here you are consuming infrastructure resources and to control the costs is key.
- Model testing: you test the models with different variants and compare different performances each other. This is a race to increase accuracy, gain performance with respect the goals you have defined and fight against different data bias.
- Evaluation: this is a critical moment for the solution. Is the performance of the model and its accuracy enough to fulfill the business goals defined for the project? Here the project manager has to transform all results in tangible deliverables that are (or not) able to fulfill the business goals. Sometimes the results do not meet the requirements and this has to be explained. A good structured root cause analysis is key to show it to the relevant stakeholders. This can be considered a major milestone for the project.
- Production deployment: You have the Ok for the model and now you have to integrate it into a formal application that will consume it. The work with the applications team to integrate the model into the applications lifecycle and the operations requirements takes a lot of time, specially when it’s the first model to be moved to production environment. Here you have to improve the inference execution in terms of time and cost.
- Monitoring of data: Operations team, business owner team, or someone in the organization has to monitor the data being used by the model. Continuous monitoring of incoming data can help to understand why the model is not bein as accurate as expected and enables to retrain your model on newer data if the data distribution has deviated significantly from the original training data distribution. This step for production is key to do not harm the operations being executed by the model.
- Model update: In case data changes (amount, distribution, quality…..) or you have identified new business reasons to update the machine learning model, then you should proceed to work on it. Here, it depends how the organization is operating: value streams under a portfolio, new perfective project for the support team, etc.
Once you have reach last point, you will start again. If you don’t do it, data will change, then your original solution will not be valid anymore.
This diagram shows how each one of the steps is linked to other ones. See how there are many different loops that can happen during the lifecycle.
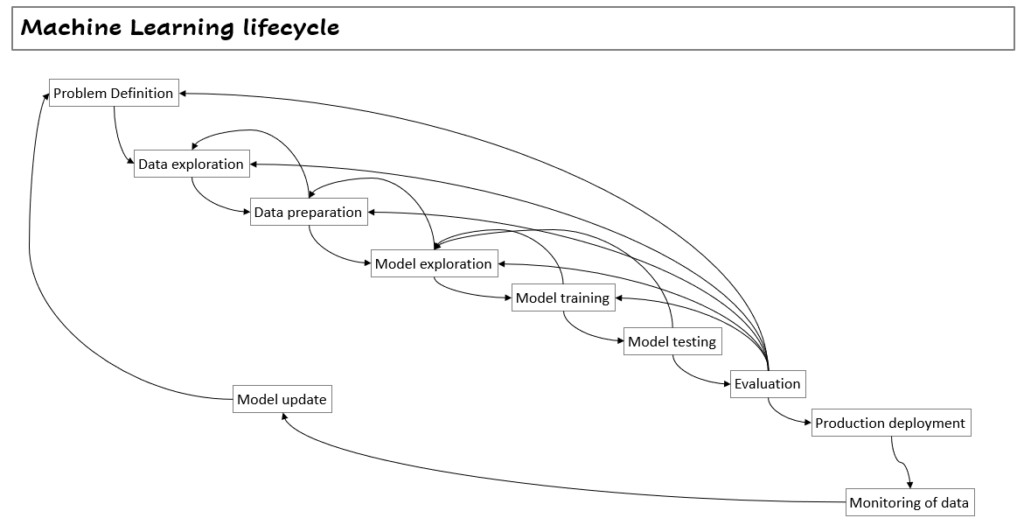
Work Breakdown Structure for a Machine Learning Project
The amount of real loops that can happen during the lifecycle makes that the definition of a Work Breakdown Structure (WBS) and a proper project schedule is very hard.
By this reason, to many organizations start learning about how to implement this lifecycle, and once they have performed several times, then they start to define ranges of effort depending on the activity of the lifecycle.
If you pretend to perform an estimation of effort in detail by components of the lifecycle without previous experience on the context where you are going to execute, then I’m 99% sure you will fail.
Come on!! show me at least a basic WBS!!!
Ok, here you have something basic:
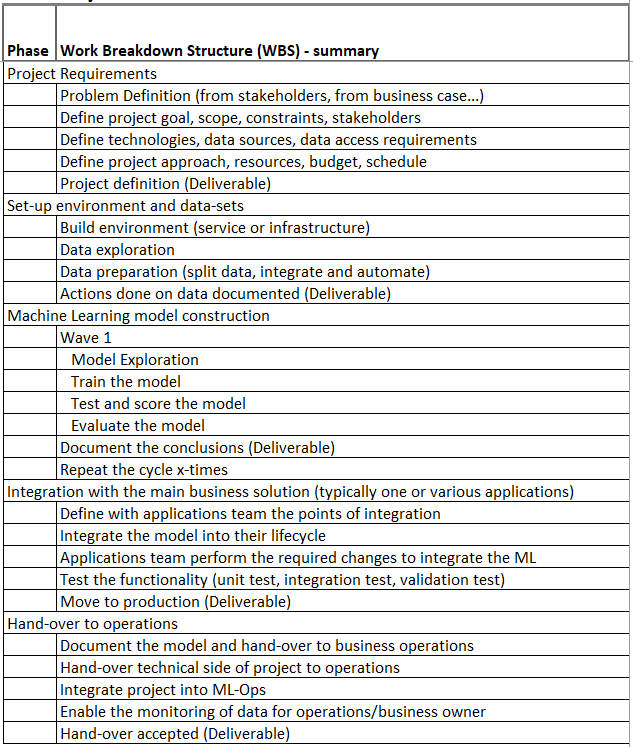
Common misperceptions:
- Most of the time is spent in the Modeling, Training, Testing stage.
- Integration with the business process that consumes the Machine Learning solution is straight forward.
- Once the model and the code is validated there is the need to perform an exhaustive version control. You are going to move something to production and it has to have the right maturity.
- Some people think that once you have the code in production no more changes are required. This is just the opposite, even in solutions to be used by manufacturing machines, there are changes in data distributions that require adjustments.
- In fact your data will probably change more than you expect. Do not let this information to come from people, define thresholds and monitor the data. Don’t let bias to provoke wrong decisions.
- You better perform cost control on infrastructure resources as soon as you can. Your project will not be the first one that is cancelled when you realize that you have already spent all cost in the first training event.
- Cost control during the execution on production is something to be performed, as you may have surprises too.
- Trends are not perpetual, they change as the data change. You have to keep your mind opened to these type of situations.
- Labelling data is very expensive, when you are able to find data labelled available, or you can automate part of the data: evaluate and consider the pros/cons. Probably from the cost point of view, it will be better. Things as a mechanical Turk may be useful.
- The cost of automation is a hidden cost that needs to be addressed, when you are running a project of this nature where the data cycle is run continually, you need to have into account.
- Machine learning (ML) inference is the process of running live data points into a machine learning algorithm (or “ML model”) to calculate an output such as a single numerical score. Everybody recognizes the training process consumes a lot of resources in terms of CPU, GPU and memory. But people often forget that inference is run many times, and depending on the use it can easily cause huge amount of consumption. There are mechanisms, algorithms and tools to turn the executable code of a ML model into a more efficient executable.
- Always get help from business people or the people that have the domain knowledge. Your project will be better in many ways. Take the time to provide the right training on ML, so they can be engaged properly.
Other things to take into account:
- Infrastructure activities depends on the environment you are working on. Few projects are build on proprietary infrastructure, majority are services that are consumed and need to be tracked and the cost should be controlled.
- When working on a value stream team under a portfolio (in terms of agile methodology), the majority of work is focused on the data and the model to be build. This increases the speed of construction for the organization.
- When business and the value stream team work on update models and increase the use of ML models to operations they do not use this type of WBS, they just focus on the ML lifecycle and the completion of goals.
- The strategy taken when defining the sampling (random or stratified) will determine some limitations and issues. As usual, you have to get a compromise.
- Data labelling is a complex step in some cases. There are tools and techniques to label data and it takes time to automate the right labelling of data. In addition to that, for large label lists, when data changes, labels can be subjected to change too.
- Some companies define a set of data as open data, offer for consumption. There is a benefit for the organization sharing it: other people will work and try to get benefit of these data sets in many different ways, finding data issues in your dataset. Usually they will provide feedback to get them corrected.
- Data security and data privacy is a topic that needs to be reviewed since inception of the project. Questions as which data is sensitive, in which degree, how it can be managed, define needs of anonymization, principles of anonymization, etc.
- Data security and data privacy is not a one stop point. As data is a live component, it can happen that we are managing unstructured data, and that during the use of that data new data that can be labelled as “private” can fall into the wrong place. It could sound crazy or very detailed, but in environments as healthcare or insurance, this needs to be taken into consideration continually.
- In some special cases, encryption is part of the equation: because some data comes encrypted, or because we have to encrypt the data in some of the routes the data takes. Don’t forget to ask about encryption requirements.
- The use of synthetic data for training is something that can be useful in some cases: data privacy, security, or unavailability of enough data. There are companies that build synthetic data respecting privacy requirements, the acquisition of this data is very common.
- The use of humans for labeling require quality processes and people checking the data quality meets expectations. This accuracy is critical for training the models under the right data.
Useful diagram from h2o.ai