
This post covers different readings and learnings I’m working to gain knowledge on Machine Learning.
At this moment, to me, there are 4 pillars of knowledge that I should gain when talking about Machine Learning. These are:
- Models & math’s knowledge.
- Software Programing: python (it’s the one I will use).
- How the machine learning initiatives are organized: lifecycle, and other things.
- Computer systems: hardware and computer configuration
1. Models & math’s knowledge
Different types of classifications to explore
1.1 Different classifiers could be exploited here from the scikit-learn library:
- DecisionTreeClassifier
- LogisticRegression
- KNeighborsClassifier
- RandomForestClassifier
- AdaBoostClassifier
- GradientBoostingClassifier
- Support Vector Machines
- MLPClassifier
- GaussianNB etc.
1.1.1 What is Regression in Machine Learning?
Regression is a technique used to predict values across a certain range. Example: consider the salaries of employees and their experience in years; then a regression model on this data can help in predicting the salary of an employee even if that year is not having a corresponding salary in the dataset.
1.2 What is an ensemble technique?
In ensemble learning, you take multiple algorithms or same algorithm multiple times and put together a model that’s more powerful than the original.
Random forest regression is an ensemble learning technique.
1.3 What is Random Forest Regression?
This is a four step process and our steps are as follows:
- Pick a random K data points from the training set.
- Build the decision tree associated to these K data points.
- Choose the number N tree of trees you want to build and repeat steps 1 and 2.
- For a new data point, make each one of your N tree trees predict the value of Y for the data point in the question, and assign the new data point the average across all of the predicted Y values.
Source: here .
1.4 One hot encoding
One-hot encoding is used in machine learning as a method to quantify categorical data. In short, this method produces a vector with length equal to the number of categories in the data set. If a data point belongs to the category then components of this vector are assigned the value 0 except for the first component, which is assigned a value of 1. In this way one can keep track of the categories in a numerically meaningful way.
- [0,1,0,0] // female
- [0,1,0,0]
- [0,1,0,0]
- [0,1,0,0]
- [1,0,0,0] // male
- [1,0,0,0]
- [1,0,0,0]
- [0,0,1,0] // gender-neutral
- [0,0,0,1] // other
- [0,0,0,1]
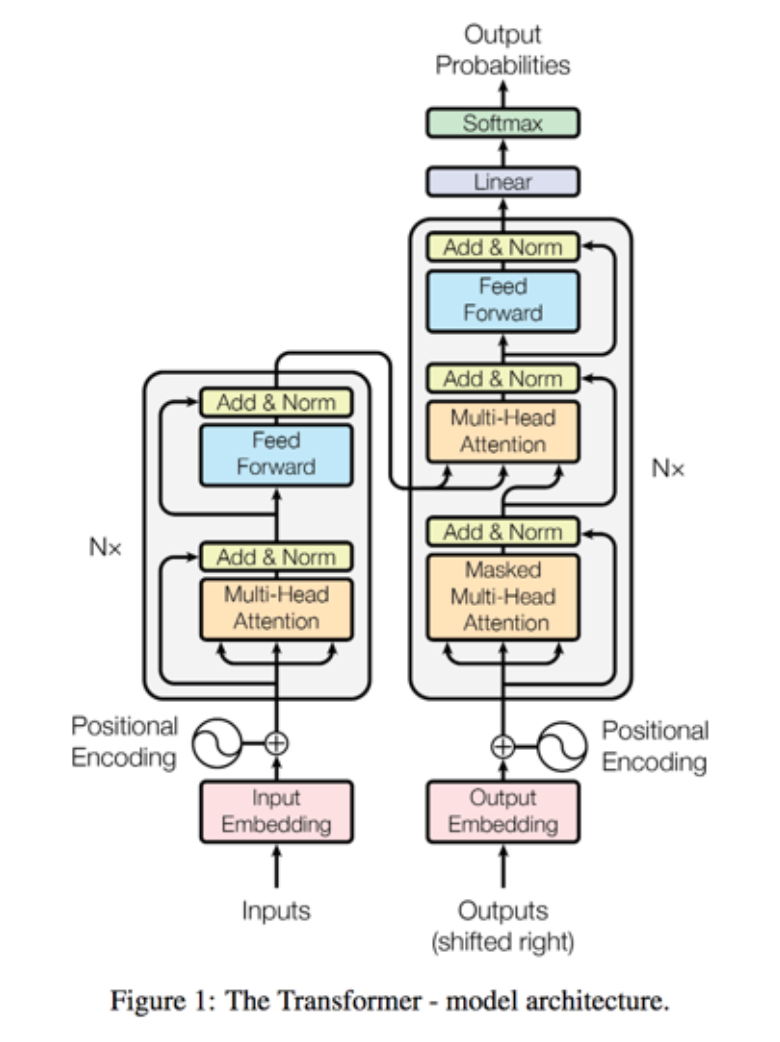
1.5 What is a transformer neural network?
Types of neural networks:
- Vector to sequence model: image identification to text.
- Sequence to vector model: sentiment analysis
- Sequence to sequence model: language translation.
This architecture appeared in 2017.
This video explains it really well: https://www.youtube.com/watch?v=TQQlZhbC5ps.
Parts of a transformer
- Embedding: one instance of some mathematical structure contained within another instance.
- Positional encoder: vector that gives context based on position of word in sentence.
- Encoder block, Attention: what part of the input should we focus?
- Decoder: linear layers and attention layers.
- Linear layer: feed forward layer.
- Softmax: probability distribution.
2. Software Programing
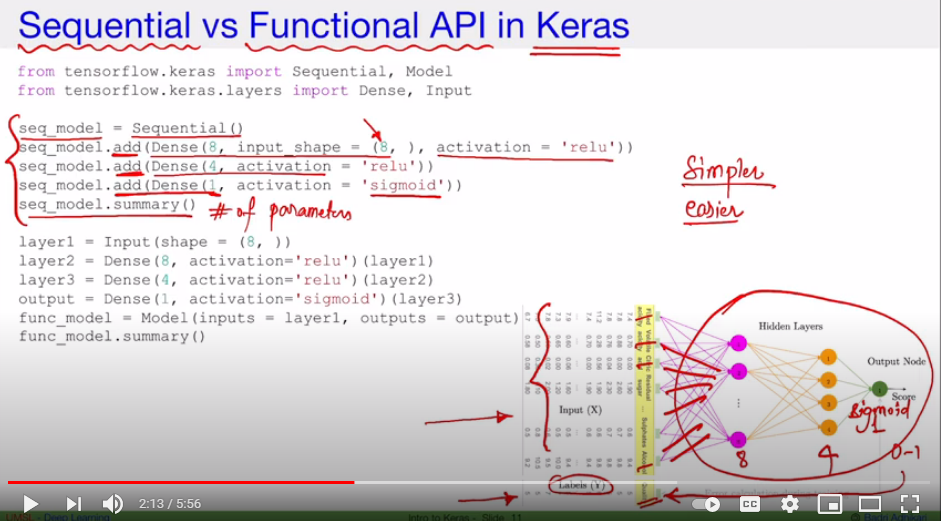
2.1 A basic notebook running sequential model with Keras
This notebook was very useful to review it and understand how to run Keras sequential model.
This video explains really well how it works with a picture: https://www.youtube.com/watch?v=EvGS3VAsG4Y
2.2 What is “Epochs”?
It can be described as one complete cycle through the entire training dataset and indicates the number of passes that the machine learning algorithm has completed during that training.
3. How the machine learning initiatives are organized
3.1 Steps for a complete rich code
This post contains the whole list on a notebook:
- Exploratory Data Analysis (EDA)
- Data Cleaning and further EDA
- Feature Engineering (FA)
- Train/test split of data
- Classification and model
- Make Predictions on True Test Dataset
- Submit solution
- Analyze and evaluate predictions
- Room for improvement
https://www.kaggle.com/gunesevitan/titanic-advanced-feature-engineering-tutorial
3.2 How to solve Time Series problems.
4. Computer systems
Here a bunch of things related to GPUs and other computer’s stuff.
- GPUs benchmark: https://gpu.userbenchmark.com/
- Jetson Nano, a competitor of Raspberry: https://www.nvidia.com/en-us/autonomous-machines/embedded-systems/jetson-nano/education-projects/
Tunneling project: a machine learning project can be seen as a mining project in a way that you do not know where the result is going to be, so you have to dig several tunnels to find it.
In machine learning, the infrastructure project that has the objective of enable the required infrastructure and be able to keep the cost under control.