The publication of the pricing deck for the OpenAI models focused on Enterprises gave me some time about how to approach this from the point of view of companies.
I have started with this Wardley Map
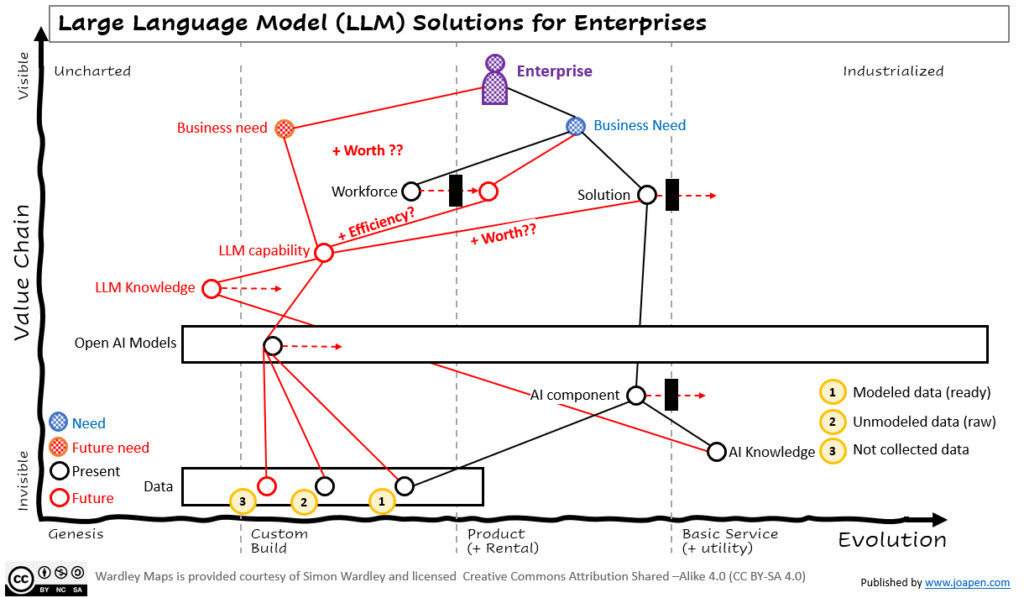
The starting point
I will start with the actual situation of a given company.
- Companies have business needs, they build solutions (products/services). To do that they build “AI components” based on AI Knowledge.
- I assume that AI knowledge is high/mature. If this is not the case, then the company is already in trouble in terms of innovation on this space.
- The data required for these AI components of a solution exist, is modelled and it’s ready (#1).
Where to start?
We all have to start building “LLM knowledge“, which means that it will enable the organization to identify proper solutions, start discovering the complexity of these solutions, understanding the data needs you have (#3 Not collected data).
The LLM models are already available, for instance using OpenAI, but it’s the starting point.
Once the “LLM knowledge” progress the company can start asking relevant questions.
- Are these “LLM capabilities” +worth for the current solutions we are providing to our customers? probably no (due to the user stories that these solutions are different).
- Is the value/investment balance worth enough to invest on it?
- Are these “LLM capabilities” valuable to increase the efficiency on tasks performed by people?
- Have we identified a potential “business need” that could be satisfied with the use of these capabilities?
- Are we already collecting the data that is required for the potential solution? (#2 Unmodeled data (raw)).
- Do we need to collect and model other type of data? (#3 Not collected data).
- When is the right time to invest on it? What are the signals that we should pay attention to?
And I have only questions, and questions
- Do we have the right amount of data for implementing new solutions?
- What are the new quality thresholds we have to define to consider during the implementation of a LLM capability?
- Do we understand the levels of uncertainty that are managed by these languages?
- Do we a framework on how expressions of uncertainty interact with large language models?
- Do we have to analyze how expressions of uncertainty interact with large language models?
- How does the model accuracy suffers when models use expressions of certainty?
- How does the model accuracy suffers when models use idiomatic language?
User stories covered by these solutions
One of the major uncertainties of the OpenAI models is the user stories they are able to cover. If you look at the user and how these solutions can satisfy their needs the range of fit makes me think that:
- Right now is very focused on certain scenarios.
- There is potential growth that is still not explored.
I guess one of the big challenges for OpenAI is to educate the companies about how they can get competitive advantage on these solutions and focus on the generation of great success cases.