Machine Learning projects come with a lot of complexity in terms of organization and this type of projects are not just to be a challenge for the consumption of infrastructure services, but it’s going to be a challenge to the ability of the organization to deliver in a reasonable speed.
Let’s start with some basis and assumptions
Let’s assume that any organization that delivers software have this type of job to be done when delivering this software:
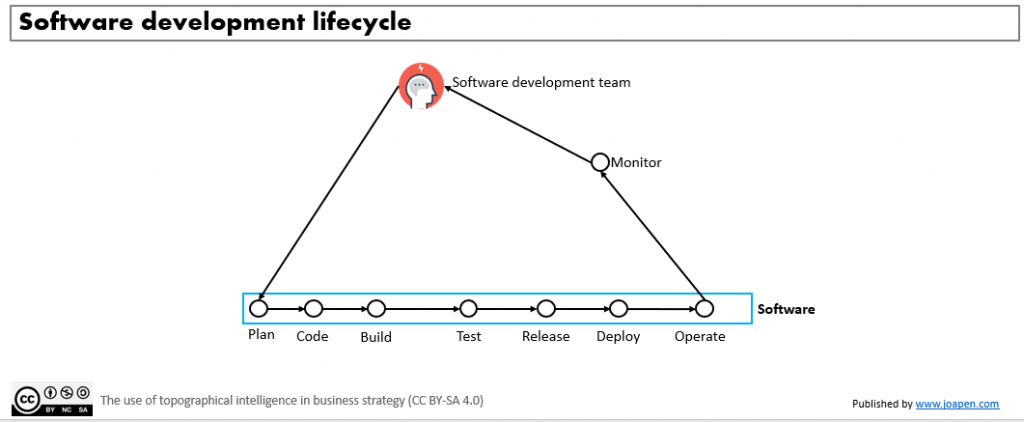
There are organizations that are delivering all manually and there are others that have a high degree of automation. Independently of the size of these teams, we can say that the ones that have evolved to a more automated and coordinated method of work have, a priori, some benefits such: speed of delivery, less rate of repeated issues….
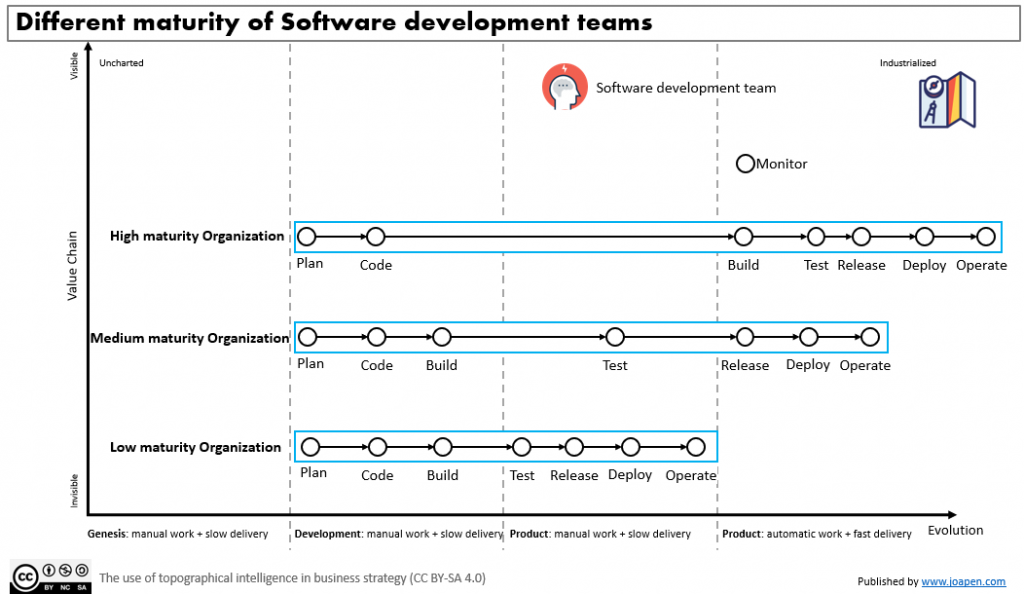
I have modified the Y axis of a Wardley map to reflect the evolution of software development teams in the map:
- Genesis: manual work + slow delivery.
- Development: manual work + slow delivery.
- Product: manual work + slow delivery.
- Product: automatic work + fast delivery.
Note that in the 2 stages of the product, not all work is going to be manual or automatic, but it refers to the main amount of work performed on a given activity.
Once we understand the evolution axis, I have drawn different potential types of organizations depending of how evolved they are:
We have to assume this is a hypothetical scenario, due to the reality is that there is not perfect correlation between automation and real fastest delivery, but let’s simplify it in this way so we can make this easy to explain.
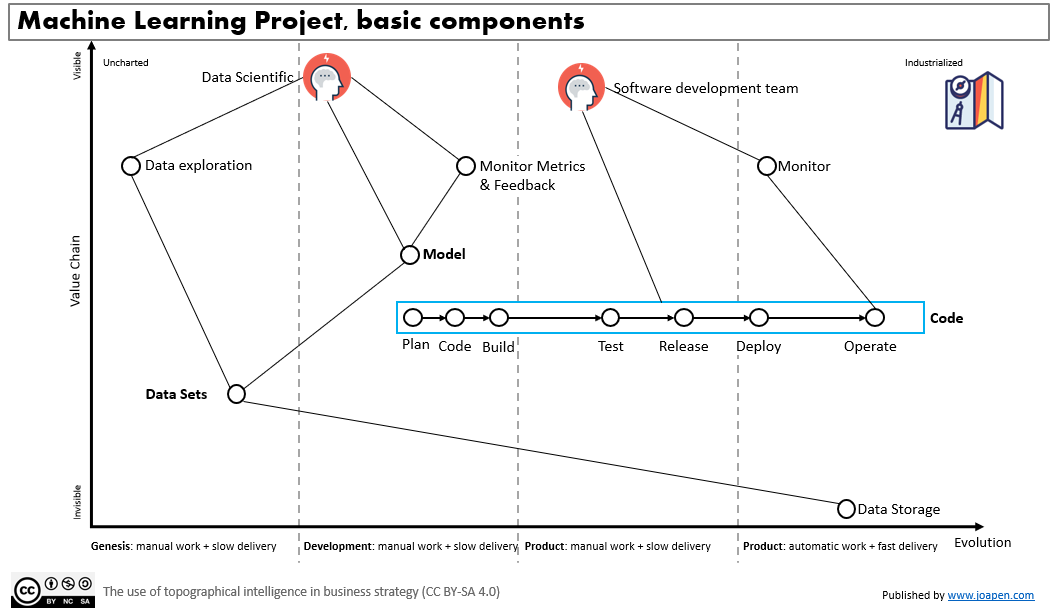
At the end of the day we have code, that is created from requirements and technical design and it evolves till be moved to production and is operated by users. Code is one dimension and the data is the second dimension we should pay attention too. The components drawn are the ones related to the DevOps, and depending on the maturity of the organization they will be implemented in different ways.
We can distinguish between 3 types of organizations, depending of how mature they are in terms of delivery of software:
- High maturity: High speed of delivery.
- Medium maturity: Fair speed of delivery.
- Low maturity: low speed of delivery.
This speed impacts the business in different ways: ability to reach the market in a timely manner, ability to evolve with the changes imposed by market, regulator or competition, etc. In a nutshell: it defines your ability to compete.
What happens when on an organization decides that they want to implement machine learning projects?
The first thing that happens is that the 2 initial dimensions: code + data, we are going to jump to a more complex model with model as new dimension, but in addition to that, the datasets are going to be more complex too, due to the volume of data you want to be able to manage. Graphically speaking what it came to my mind was this:
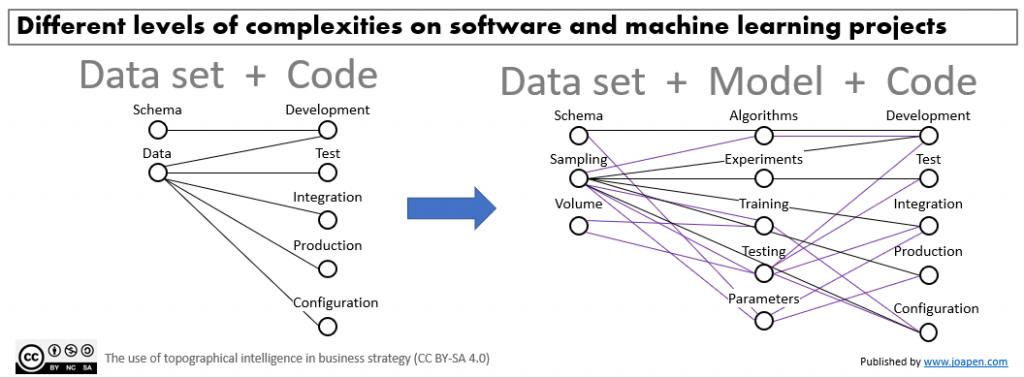
We have to manage this complexity, in one way or other. And what we already have implemented will have consequences on this.
I know, we always can create separate teams to manage different type of projects, but at the end of the day you will have to integrate the software project with the machine learning project, and another relevant thing is: how much it cost to duplicate basic capabilities?
If we try to map a simplified map of a machine learning project we could have this for instance:
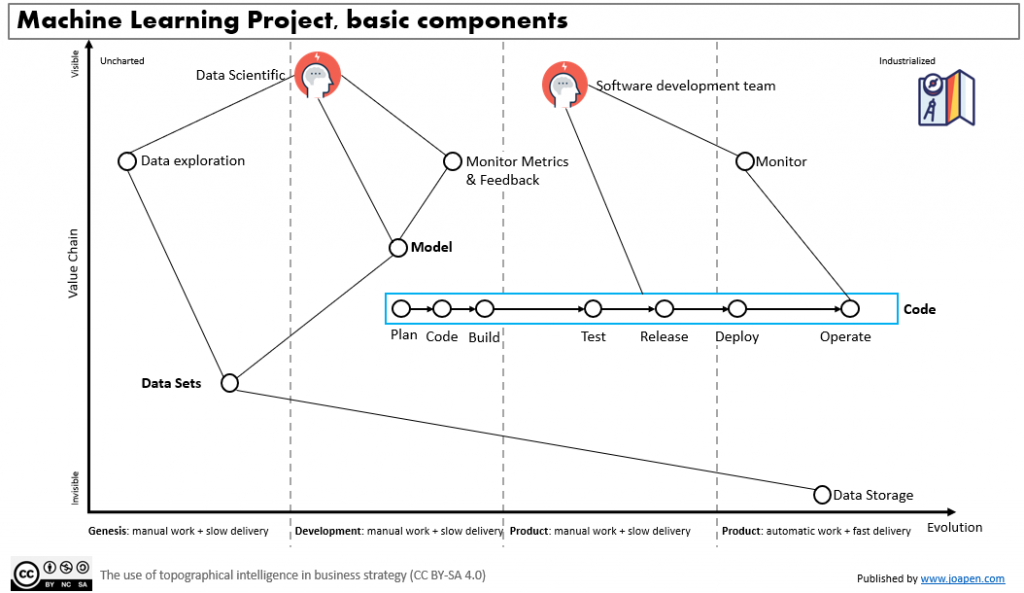
Initially on a Machine Learning project almost all is going to be mainly manual, new tools and best practices will be adopted with the time and the maturity of the teams. It will have their own evolution and they should look at the Machine Learning Operations practices as a reference of best practices for the organization.
Now let’s look at more components of the machine learning project in conjunction with the software development:
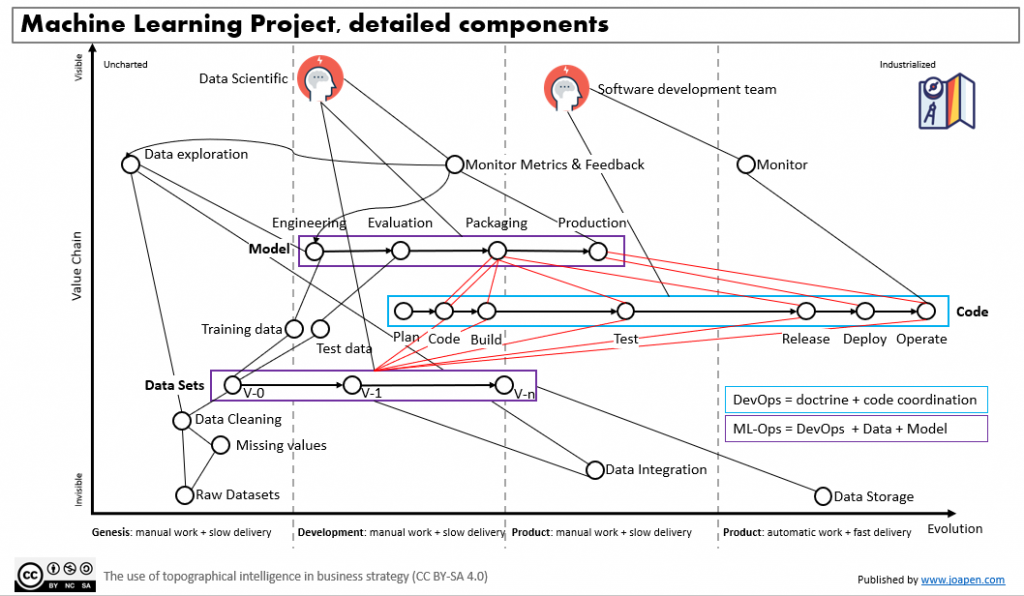
On this map I would like to pay attention to three things:
- Model: the lifecycle of a machine learning solution has its own lifecycle and we have to integrate it properly with respect the other dimensions: data sets and code.
- Data sets: to have the right data sets for a machine learning project is a very consuming side of the project. We will have to move high volumes of data, we will have to clean, integrate and label data to enable the models to have the right data baseline to work. All this is going to be manual work with the support of tools or data providers that provides data sets.
- Red lines: I have drawn some red lines to connect the 3 dimensions previously mentioned. You can argue that some of the lines are not right, and I agree with you, but my point is that independently of that, the complexity of organize all this is a little bit more complex that organize data + code.
Now, let’s talk about speed of delivery
I would like to be able to draw the speed of delivery of an organization using Wardley maps and I do not know if I will be able to do it. But let’s try it.
To do it I will use the previous map, that was drawn using the “Medium maturity Organization” for software delivery, and I will change to “high” and “low” maturity.
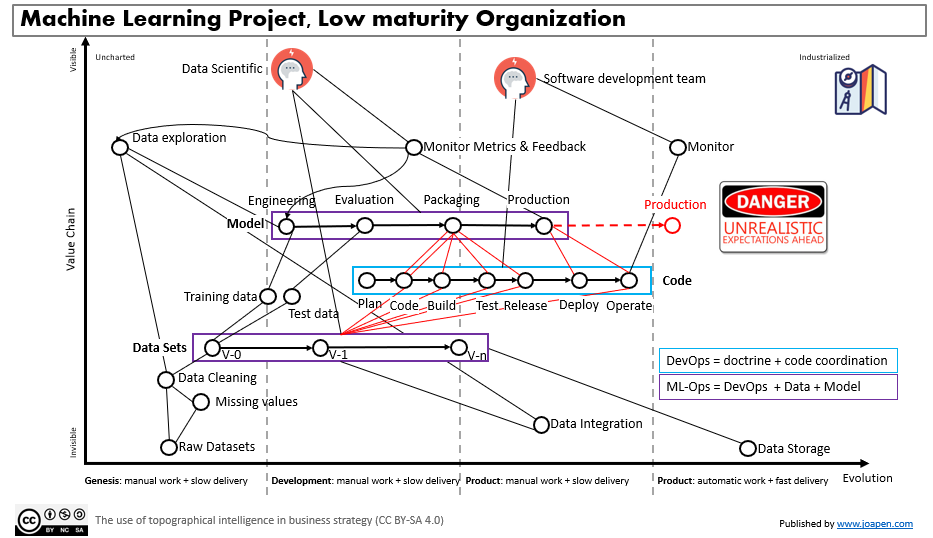
The low maturity organization
We can try to implement ML-Ops best practices and try to automate parts of the delivery in an context where all is manual, and this is initially something unrealistic. We have to remember that DevOps is not only automation, it has a lot of doctrine or culture behind of it, and a low level of DevOps culture on an organization makes unrealistic to implement on other sides of the organization. I do not say that is impossible, I just sat that is very uncommon that it happens.
At the end of the day, with all delivered in a manual way, we will have a low speed of delivery, and with the new machine learning projects slower, due to the new complexities added by them.
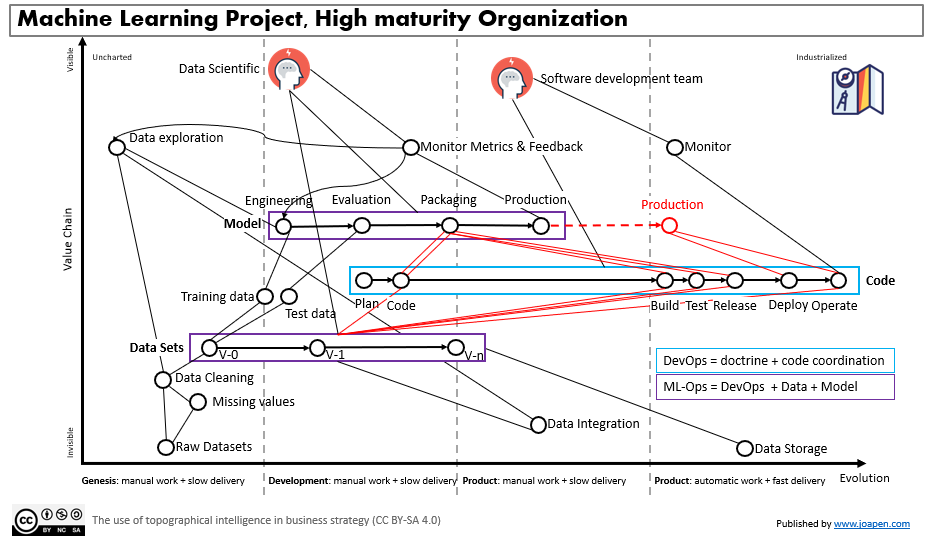
The high maturity organization
In an organization where the DevOps culture, best practices and the proper tools are deployed, we will have some parts of the software delivery already automated with a decent degree. The integration of new type of projects such a machine learning project, where new complexities are added will take the organization to have to adapt to these new requirements from the “data scientific”.
If the understanding of the new complexity is recognized is in part thanks to the DevOps culture; then the existing processes and tools can be adapted to these new needs.
This will leave the focus on the machine learning main components: data sets and model. The speed of delivery of these components is independent of the rest, but once we have stablished a speed of delivery, the DevOps culture will put the following question on the table: what can be automatized?
I’m almost sure that they will find something to automate when the machine learning components will be mature enough. Once done, they will automate it and they will accelerate the speed of delivery in a consistent way.
Closing
These are the main reasons that I think that DevOps is important for an organization that wants to implement Machine Learning initiatives.
Please, if you have some suggestion or feedback, please let me know.