If you are reading this and you are not me, you should navigate to this link: https://ml-ops.org/
There are so many basis and nice charts that explain What is Machine Learning Operations (or ml-ops). I’m doing a summary for me 🙂
Definition of MLOps
The term Machine Learning Operations is defined as “the extension of the DevOps methodology to include Machine Learning and Data Science assets as first-class citizens within the DevOps ecology.
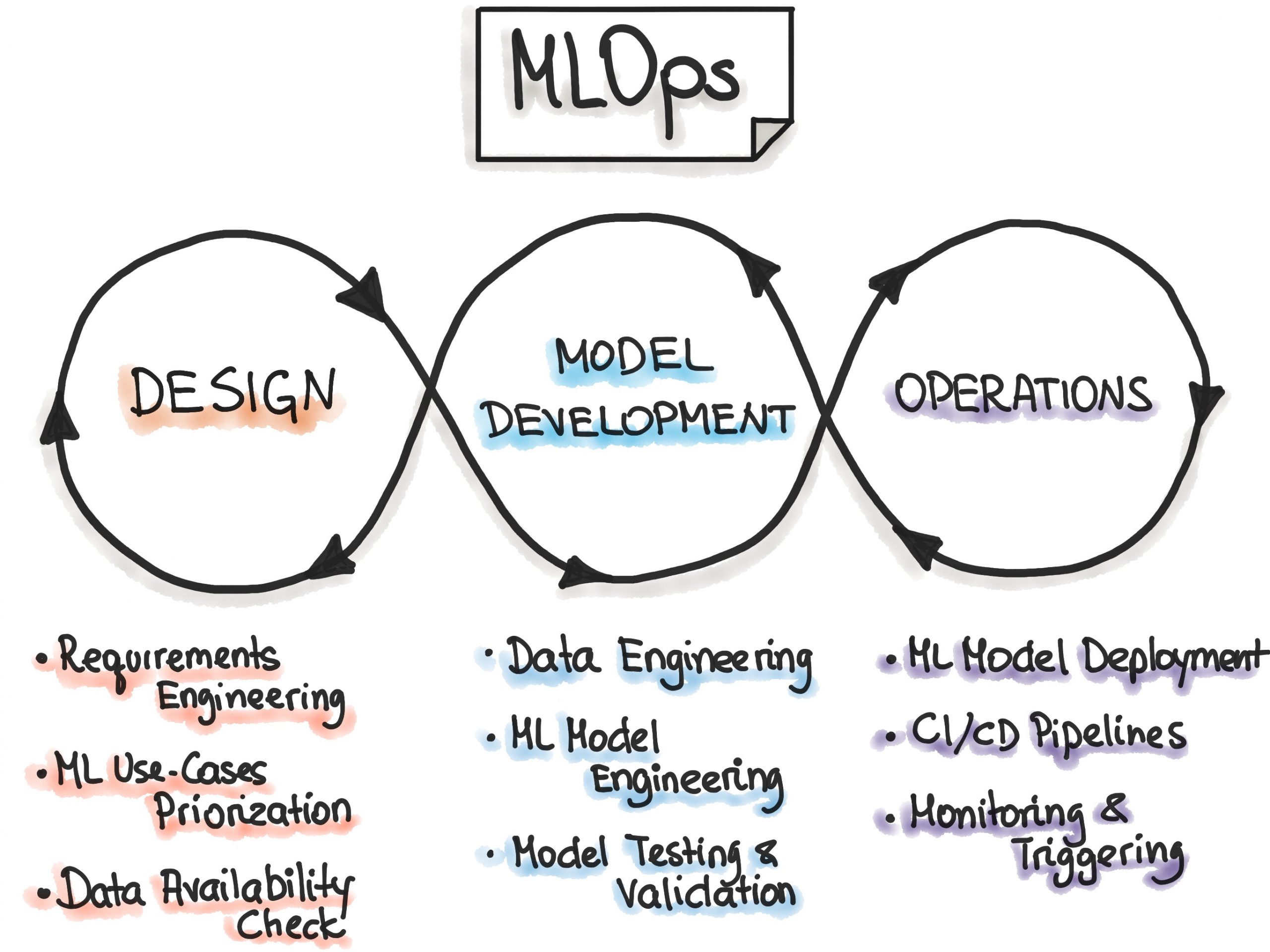
Overview of the End-to-End Machine Learning Workflow
The main phases are:
- Data Engineering: data acquisition & data preparation,
- ML Model Engineering: ML model training & serving, and
- Code Engineering :integrating ML model into the final product.
Iterative-Incremental Process in MLOps

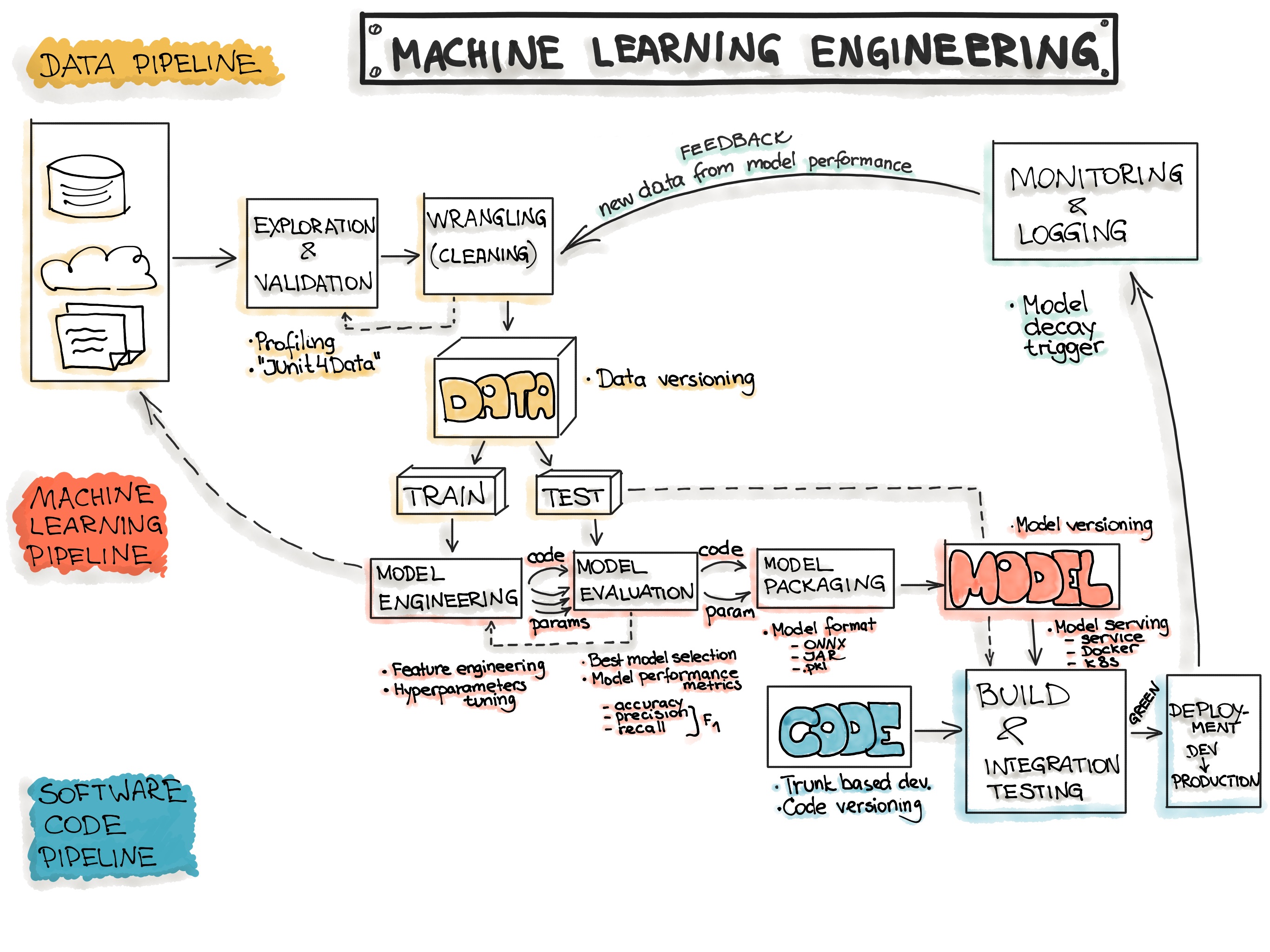
Automation
The level of automation of the Data, ML Model, and Code pipelines determines the maturity of the ML process.
- Manual process
- ML pipeline automation
- CI/CD pipeline automation
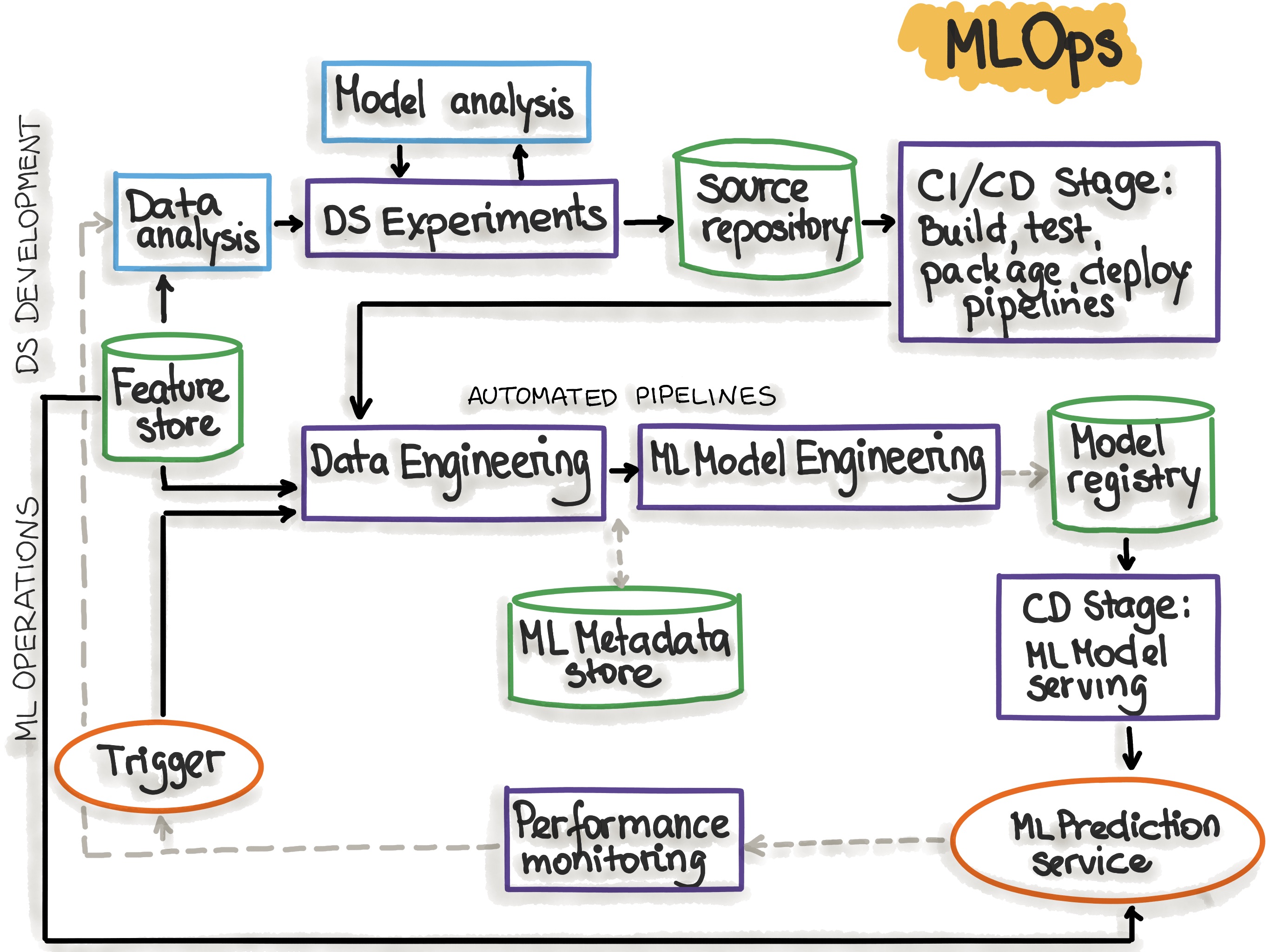
The following picture shows the automated ML pipeline with CI/CD routines:
Data Version Control
If you have the lifecycle of your code operating under DevOps and you are using Git to manage all this, how do you manage the versions of data when adding machine learning projects? One possible answer is: Data Version Control.
DVC.org is an Open-source Version Control System for Machine Learning Projects. They have some nice videos where you can see how it works and how they implement so many of the best practices from ml-ops.
For instance, this introduction video: https://www.youtube.com/watch?v=UbL7VUpv1Bs&t=2s
Many necessary processes are included in data science. The programming languages are one of the key components around which data science is built.