Background and purpose
This Wardley map tries to visualize how innovation and learning process can potentially work on a software organization with a high amount of users.
These type of organizations understand that the learning process and the acceptance of a controlled level of failure is key to face the uncertainly and finally innovate.
I have done a map, and a review of doctrines that can be useful to draw my view about it. Climatic patterns and gameplays require more specific context, so this time I will skip it.
My expectation sharing this map is to get feedback and get from you more variables of this proposed equation of innovation.
Where does innovation happen?
Innovation happens in the genesis of something new. A new act, component, feature or practice that is not well known, it has potential value and there is a lot of uncertainly around it.
The doctrines
If we look into the Wardley’s doctrines table, we can highlight some of them as required or desired in an organization that pretends to innovate. I have highlighted a lot of them because I’m thinking about different types of organizations.

I would like to pay attention to the learning doctrines:
- A bias towards the new: be curious, take appropriate risks, and enable the organization can have room for it.
- Listen to your ecosystems: you are creating a software product, you should be able to get data about how your users interact with your product.
- Use a systematic mechanism of learning (a bias towards data): a process with some ground opened rules that enable the people working in the organization to define hypothesis and perform experiments.
- A bias towards action (learn by playing the game): experiment, experiment and experiment.
The map
This is the draft proposed map:
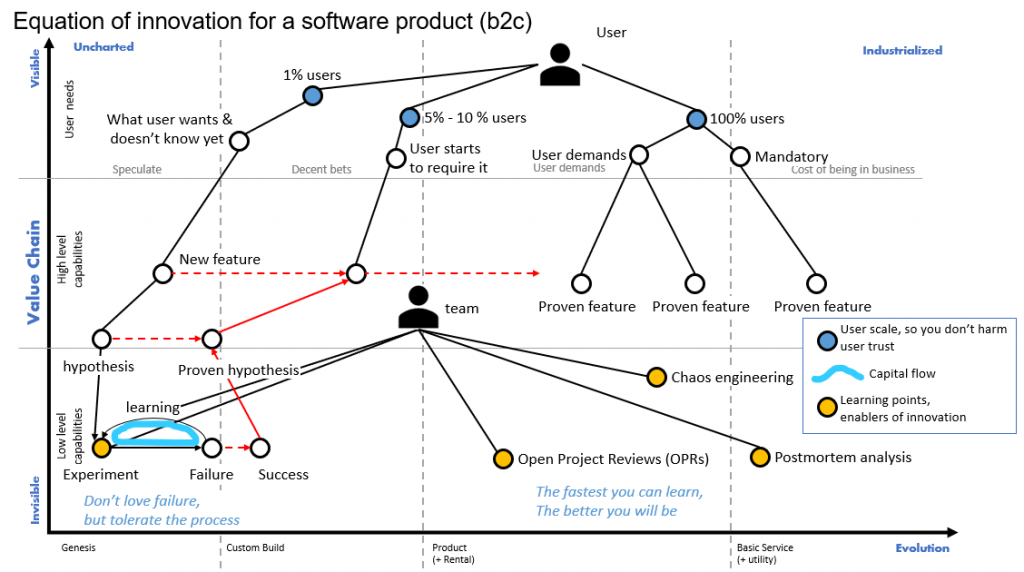
The first layer of the map (blue components) represents different segments of users, where you will use to experiment, get feedback and be able to learn from it: a bias towards data and avoiding to harm your users. In other environments this is more difficult, but major software companies have these type of mechanisms, working on.
The second layer of the map are user needs, that goes, reading from right to left, from mandatory needs the user demands, to the needs that even the user still does not know s/he would like to have.
This take us to the next level of the map: the capabilities of the software. We will have proven features that work and are accepted/required by users. And we have the need to discover which would be the next feature that really is going to be valuable and a differentiator for the company. To do that, the team will set an hypothesis, and will try to define it as best as possible.
Once the hypothesis is defined, the team will try to prove the conditions to enable that the hypothesis is valid. How? through experiments.
The experiments, in some way, are limited and controlled acts of change for the user that challenge how s/he interacts with the software, and it returns a result. This bunch of data gathered from a limited number of users is analyzed and we try to determine if the experiment was successful or a failure.
Here, an organization with tolerance for the failure, will use this information as learning about how not to do something and be the basis to define the next experiment. I have drawn a blue line of “capital flow”, that is the desired controlled investment that the company has put on this work. Here is where a big amount of learning happens. It’s a bumpy road as nobody likes to fail, and normally there is a lot of pressure to have results.
“I have not failed, I’ve just found 10.000 ways that won’t work”.
Thomas Edison
Suddenly, after n-experiments, something happens: an experiment proves the hypothesis, and this mean we can refine this feature to capture what was proven and them move to next stage. This could be to make the percentage of users to be bigger, or just to offer it to everybody.
It is at this point where I would say that innovation has happened: you have listened your users, have defined an hypothesis and have proven it giving back to the software a new feature that supposes a differentiator with respect your competitors.
Open projects reviews
Above, on the list of learning doctrines, you find a bias to the new, listen your eco-system, a systematic mechanism of learning and bias towards data. So well, open project reviews have work on all of them.
I know these type of reviews became popular in Amazon, and they have extended to many other companies that lived this in Amazon and that have taken the idea for their own companies.
Basically, a senior lead organize a project review where the responsible of a given unit is requested to report about the results of the unit, major challenges, metrics, etc. The written report is sent 2 days before the meeting. The meeting is opened, other employees can attend but without authority to ask questions, this is reserved for the senior lead a few others. The way to handle these meetings is key and the culture and the predominant doctrines of the organization will brand how it will be done.
The benefits are very wide, but in general:
- The senior lead will have the opportunity to set expectations with the business unit lead, and all the attendants will be hearing and learning from it.
- When things go well, the exposure you have can be challenged but when things go wrong the exposure to tough questions will serve in so many ways. At the end of the day, the senior lead want to understand that the things are under control and there is a credible action plan. In any case, all attendants will be hearing and learning.
- These meetings are an act of public accountability and the reactions and style of both sides of the table: senior lead and unit responsible will be tested publicly.
- The senior lead, knowing there are more people attending the meeting will be able to put in place constructive criticism, and can add more comments and questions that enable the attendants to learn more.
- People attending the meeting from other units can understand better what this guys are doing and this cross information is gold in organizations where you work in small teams and you can fall in the trap of being so much focused on your stuff and not listening what’s happening around you. They can also understand that some functionalities they are working on are already implemented on that other team.
- For the new employees of the company, this is very quick way to understand how things happen in so many ways.
There are risks, and it’s important to understand them:
- You have to balance the feedback in a smart way, so this open environment does not turn into an environment of fear.
- You have to be able to manage the tension in the proper way, and focus the review in a very assertive manner.
The ultimate goal of these meetings is to help everybody to learn faster.
Postmortem reviews
These sessions and documents are very popular and used across the software industry.
As the reader probably knows the concept is to start with a failure and through the consecutive use of “why?” you dig into the root cause of the situation and you usually are able to gain understanding of the reasons the issue happened. Normally the issue is a problem in an organization.
Here the maturity of the organization in terms of culture, in terms of practices and in terms of tools is key. A matured system where almost everything is automated, there are good practices extended in the team and there are the right tools to implement guard rails and protection to the environment, is not the same than an environment that lack of all this. But in anyway, these reviews will provide room for improvement.
Chaos engineering
This term comes from chaos monkeys, very popular term extended since Netflix created a tool that randomly reboot the servers to understand that the stability mechanisms that route the users to other places and the recovery systems are really working.
Chaos engineering is the discipline of experimenting on a distributed system in order to build confidence in the system’s capability to withstand turbulent conditions in production.
Needless to say how much learning the operations team will get from this practice. In scalable environments where you have to tight your costs and ensure the users are attended, this is mandatory.
If you think that at operations teams are not required to be innovative, it’s probably because you have never been in one. There is so much complexity being handled in these rooms and innovation to improve and create better solutions and faster ways to react are incredible difficult to build.
So, the equation should have these variables
- The right doctrines and culture in the organization to enable a learning culture and the willingness to take the appropriate risks.
- The need to listen your customer and define a concrete hypothesis.
- Run experiments that try to prove the conditions that prove the hypothesis.
- Fuel all this with capital and measure the results.
- Open project reviews that enable cross learning to all attendances.
- Postmortem reviews that challenge the organization’s gaps.
- Chaos engineering tools and practices.
Which other variables do you include in your equation?