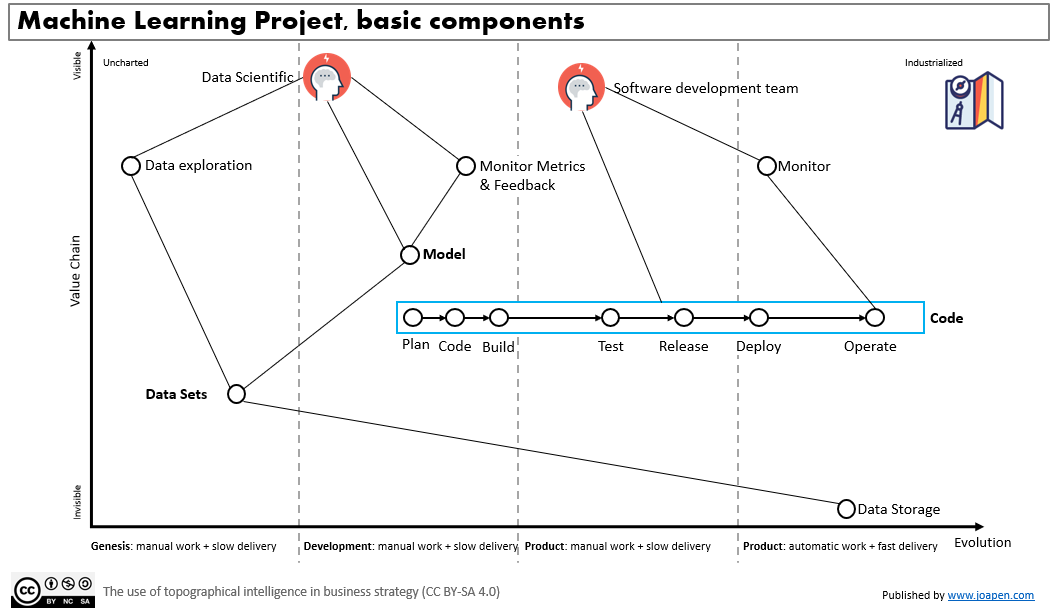
Looking for a machine learning model that hits S&P 500 daily change using market breadth data, DIX, GEX, VIX.
This is the third version of a code I have started to write while learning the concepts of Machine Learning. Changes with respect the previous versions Shift(-1) have been removed for the SPX price, I consider is an error to add it. I have added data related to DIX, GEX (since 2011) and VIX (since … Read more